- Published on
HDFS; Top-3 IPs for each hour of IP stream
- Authors

- Name
- Boakye I. Ababio
- @ibamelch
To show the top-3 IPs for each hour:
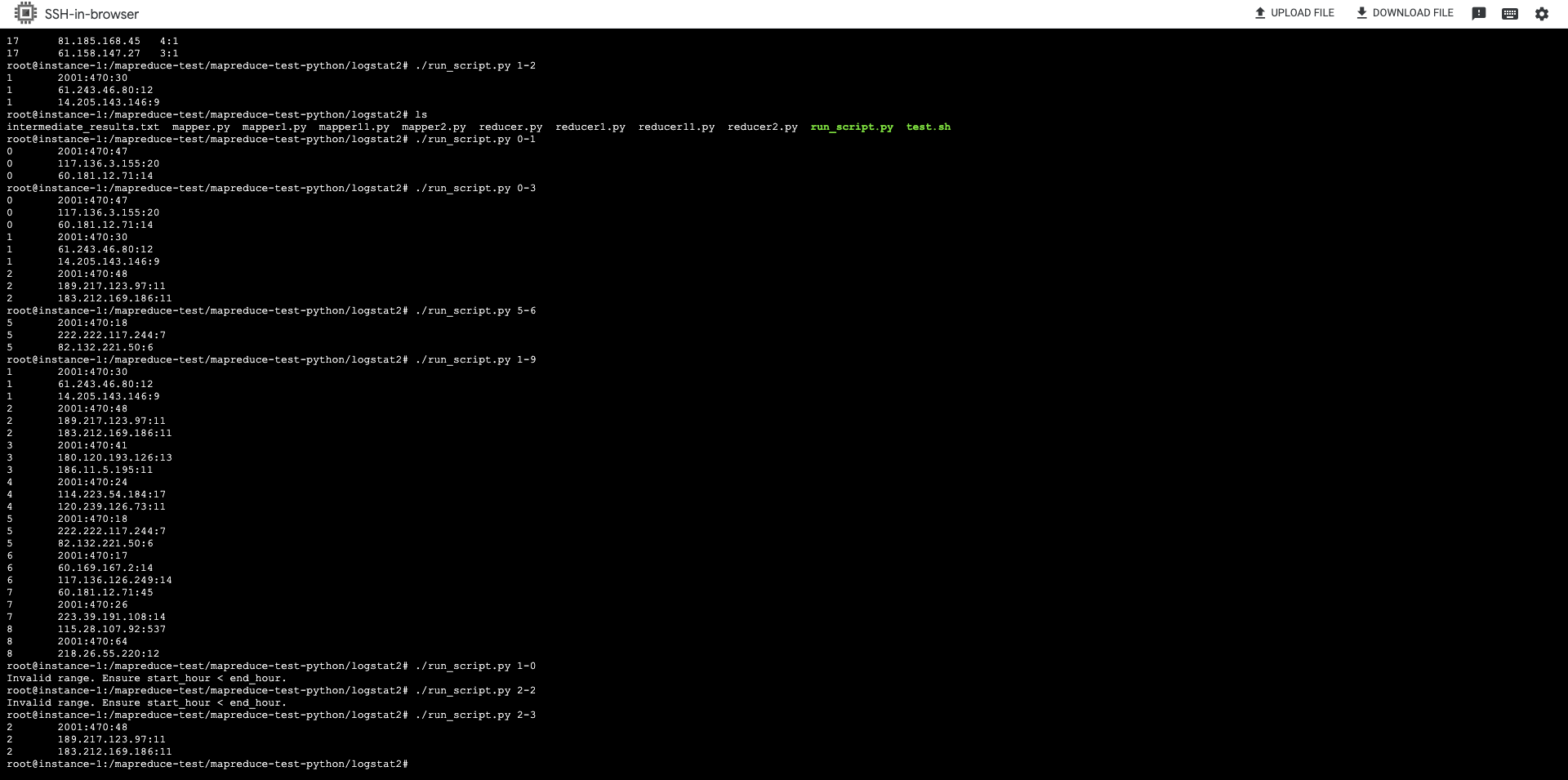
![]()
First run the following command:
cat ../../mapreduce-test-data/access.log | python mapper.py | sort -k1,1 | python reducer.py > intermediate_results.txt
And then run the following command:
cat intermediate_results.txt | python mapper11.py | sort -k1,1 | python reducer11.py
running the code:
./run_script.py 1-2
If the log data does not contain any entries for the specified hour range, the script will not output anything but it will also not yield an error.
If you strictly want to run it without run_script.py then you need to manually export the environment variables FROM_HOUR and TO_HOUR in the shell before running the command:
export FROM_HOUR=0
export TO_HOUR=1
cat ../../mapreduce-test-data/access.log | python mapper1.py | sort -k1,1 | python reducer1.py > intermediate_results.txt

Overview of the project:
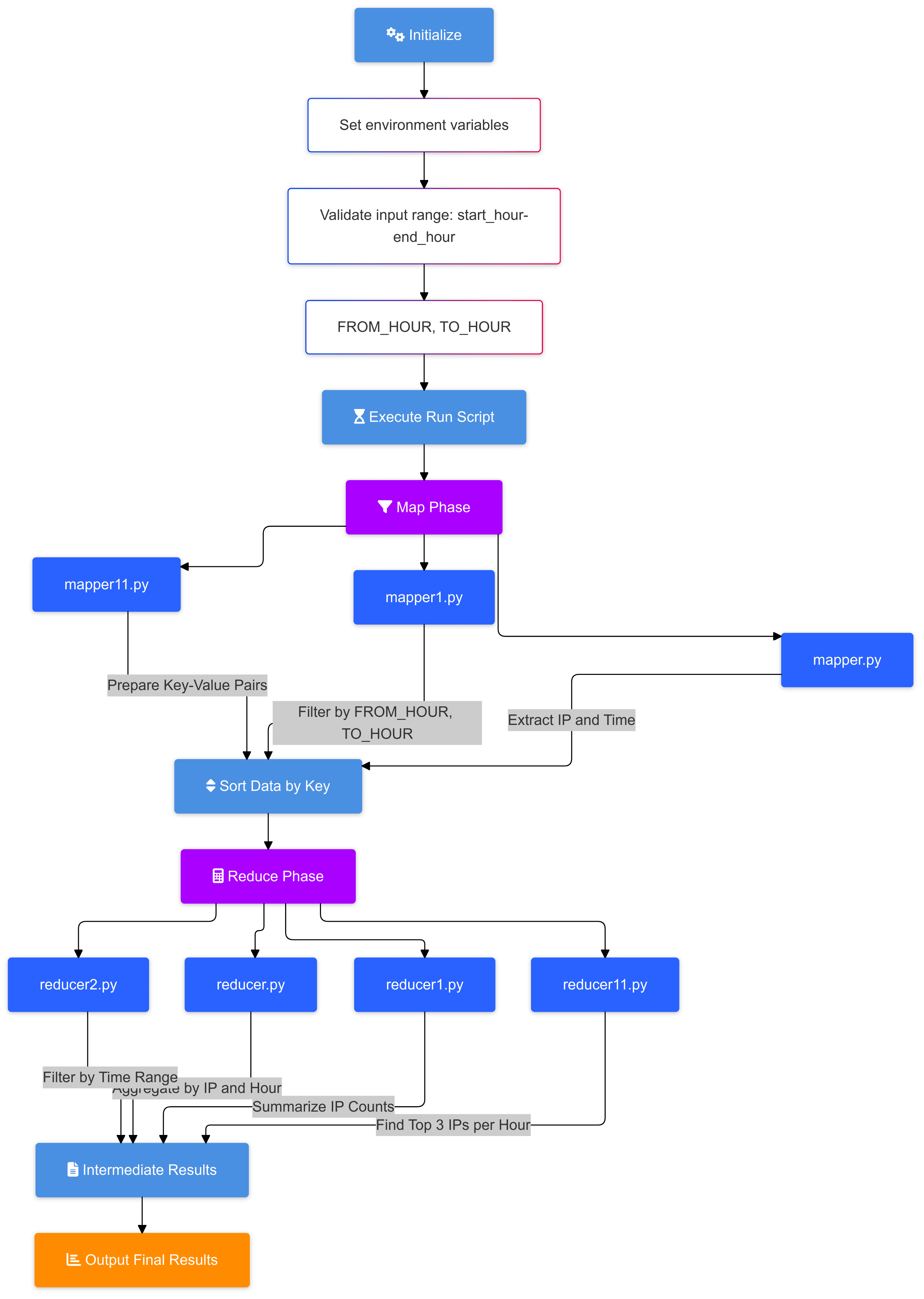
Files in the directory:
mapreduce/
│
├── mappers/
│ ├── mapper.py
│ ├── mapper1.py
│ ├── mapper11.py
│
├── reducers/
│ ├── reducer.py
│ ├── reducer1.py
│ ├── reducer11.py
│ ├── reducer2.py
│
├── scripts/
│ ├── run_script.py
│
├── data/
│ ├── access.log
│ ├── intermediate_results.txt
│
├── screenshots/
│ ├── screen_shot1.png
│ ├── screen_shot2.png
│
└── readme.md
Structured Code
Here’s how the code for the above project structure
mappers/mapper.py
#!/usr/bin/python
import sys
import re
pattern = re.compile('(?P<ip>\d+.\d+.\d+.\d+).*?\[(\d+)/[a-zA-Z]+/\d{4}:(?P<hour>\d{2}):\d{2}:\d{2}.*')
for line in sys.stdin:
match = pattern.search(line)
if match:
print('%s\t%s' % ('[' + match.group('hour') + ']' + match.group('ip'), 1))
mappers/mapper1.py
#!/usr/bin/python
import sys
import re
import os
from_hour = int(os.environ['FROM_HOUR'])
to_hour = int(os.environ['TO_HOUR'])
pattern = re.compile('(?P<ip>\d+.\d+.\d+.\d+).*?\[(\d+)/[a-zA-Z]+/\d{4}:(?P<hour>\d{2}):\d{2}:\d{2}.*')
for line in sys.stdin:
match = pattern.search(line)
if match:
hour = int(match.group('hour'))
if from_hour <= hour < to_hour:
print('%s\t%s' % ('[' + match.group('hour') + ']' + match.group('ip'), 1))
mappers/mapper11.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
print('%s\t%s' % (line, 1))
reducers/reducer.py
#!/usr/bin/python
import sys
current_key = None
current_count = 0
for line in sys.stdin:
line = line.strip()
key, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_key == key:
current_count += count
else:
if current_key:
print('%s\t%s' % (current_key, current_count))
current_key = key
current_count = count
if current_key == key:
print('%s\t%s' % (current_key, current_count))
reducers/reducer1.py
#!/usr/bin/python
import sys
current_key = None
current_count = 0
for line in sys.stdin:
line = line.strip()
key, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_key == key:
current_count += count
else:
if current_key:
print('%s\t%s' % (current_key, current_count))
current_key = key
current_count = count
if current_key == key:
print('%s\t%s' % (current_key, current_count))
reducers/reducer11.py
#!/usr/bin/python
import sys
import heapq
current_hour = None
ip_count_heap = []
for line in sys.stdin:
line = line.strip()
hour_ip, count = line.rsplit("\t", 1)
hour, ip = hour_ip[1:].split("]", 1)
count = int(count)
if hour != current_hour:
if current_hour is not None:
top_ip_counts = heapq.nlargest(3, ip_count_heap)
for ic in top_ip_counts:
print('%s\t%s:%s' % (current_hour, ic[1], ic[0]))
current_hour = hour
ip_count_heap = []
heapq.heappush(ip_count_heap, (count, ip))
if current_hour == hour:
top_ip_counts = heapq.nlargest(3, ip_count_heap)
for ic in top_ip_counts:
print('%s\t%s:%s' % (current_hour, ic[1], ic[0]))
reducers/reducer2.py
#!/usr/bin/python
import sys
import heapq
import os
from_hour = int(os.environ['FROM_HOUR'])
to_hour = int(os.environ['TO_HOUR'])
current_hour = None
ip_count_heap = []
for line in sys.stdin:
line = line.strip()
hour_ip, count = line.split('\t', 1)
hour, ip = hour_ip[1:].split(']', 1)
hour = int(hour)
count = int(count)
if from_hour <= hour < to_hour:
if hour != current_hour:
if current_hour is not None:
top_ip_counts = heapq.nlargest(3, ip_count_heap)
for ic in top_ip_counts:
print('%s\t%s:%s' % (current_hour, ic[1], ic[0]))
current_hour = hour
ip_count_heap = []
heapq.heappush(ip_count_heap, (count, ip))
if from_hour <= hour < to_hour:
top_ip_counts = heapq.nlargest(3, ip_count_heap)
for ic in top_ip_counts:
print('%s\t%s:%s' % (current_hour, ic[1], ic[0]))
scripts/run_script.py
#!/usr/bin/python
import os
import sys
# Get user input
args = sys.argv
if len(args) != 2 or len(args[1].split("-")) != 2:
print("Incorrect usage. Please provide the range in the format 'start_hour-end_hour', where start_hour < end_hour. Example: '0-1'")
sys.exit(1)
from_hour, to_hour = map(int, args[1].split("-"))
if from_hour >= to_hour:
print("Invalid range. Ensure start_hour < end_hour.")
sys.exit(1)
os.environ["FROM_HOUR"] = str(from_hour)
os.environ["TO_HOUR"] = str(to_hour)
# Run MapReduce
os.system("cat ../../data/access.log | python mappers/mapper1.py | sort -k1,1 | python reducers/reducer1.py > data/intermediate_results.txt")
os.system("cat data/intermediate_results.txt | python reducers/reducer2.py")
mapper.py: This file contains the code for the first map reduce. It reads the access.log file and outputs the IP address and the hour of the log entry.
reducer.py: This file contains the code for the first reduce. It reads the output of the first map reduce and outputs the IP address and the hour of the log entry.
mapper1.py: This file contains the code for the second map reduce. It reads the intermediate_results.txt file and outputs the IP address and the hour of the log entry.
reducer1.py: This file contains the code for the second reduce. It reads the output of the second map reduce and outputs the top 3 IP addresses for each hour.
mapper11.py: This file contains the code for the second map reduce. It reads the intermediate_results.txt file and outputs the IP address and the hour of the log entry.
reducer11.py: This file contains the code for the second reduce. It reads the output of the second map reduce and outputs the top 3 IP addresses for each hour.
intermediate_results.txt: This file contains the output of the first map reduce. It is used as input for the second map reduce.